コーディングのお勉強 @classmethod
わからなかったこと
- Classをインスタンスにするまえに、methodを呼び出せることが理解できなかった。
- 下記のclassで
test.methodtest()としたかった。
class test: def __init__(self): print('初期化') def methodtest(self): print('method_test') return self
わかったこと
class test: def __init__(self): print('初期化') @classmethod <-- こいつが必要だった。 def methodtest(self): print('method_test') return self
@classmethod
- @classmethodの使い道がわからない・・・
- methodを直接使えるのはいいけど、本当はほかにメリットがあるのでは・・・
Ridge回帰とLasso回帰について
読んでる本
- まだ途中です。

- 作者: 秋庭伸也,杉山阿聖,寺田学,加藤公一
- 出版社/メーカー: 翔泳社
- 発売日: 2019/04/17
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
ただの線形回帰との違い
RidgeとLassoの式の違い(2次式の場合)
最初の項とαの項が2乗になっているかいないかの違いがある。
- Ridge
$$ R(w) = Σ_{i=1}^{n}(y_i-(w_0 + w_1x_i + w_2x_i^{2})^{2} + α(w_1^{2} + w_2^{2}))^{2} $$
- Lasso
$$ R(w) = Σ_{i=1}^{n}(y_i-(w_0 + w_1x_i + w_2x_i^{2})) + α(|w_1| + |w_2|) $$
αはハイパーパラメータの選定はGridSearchとかでやればいいのかな?
テキストマイニング_単語N-gramモデル
最近、転職活動の一環の勉強として、「自然言語処理の基本と技術」という本を読んでいます。(データサイエンティストとして、自然言語処理も必要だと考えているため)

前回は、Yahooニュースの本文から形態素解析をjanomeで行った後、名詞をカウントしグラフ化を行いました。上記の本には、単語ユニグラムモデルと呼ばれるモデルがこの方法に該当するようです。
これを拡張したモデルとして、単語N-gramモデルと呼ばれるモデルがあり、これは、かな漢字変換エンジンで利用されているらしい。ただし、ほかにも処理(正規化・平滑化・モデルの圧縮)も行わないと使えないみたいだけど詳しくは本書では書いてないようでした。
このあたりの記述を読んでいるとこうしてブログを書いている途中で様々なかな漢字変換を当たり前にしている技術がこういう風にできているんだと再認識できてとてもよい勉強になっていると思いました。
テキストマイニング(前回の続き2)
概要
前回までのあらすじ
- 入力したURL(yah○○ニュース)から本文を抽出
- 抽出した本文から名詞を抜き出し
- 抜き出した出力はこんなかんじ

今回やること
- グラフ化して、単語の出現頻度を確認する
- グラフ化はpandasのDataFrameから行う
SourceCode
# URLを指定し、htmlデータを取得 url = u'https://headlines.yahoo.co.jp/hl?a=20190419-00000057-it_nlab-sci' response = urllib.request.urlopen(url) data = response.read().decode('utf-8') soup = BeautifulSoup(data) main = soup.find('p',class_="ynDetailText yjDirectSLinkTarget") text = main.text token_filters = [POSKeepFilter('名詞'), TokenCountFilter()] a = Analyzer(token_filters=token_filters) # 取得したデータをデータフレームに格納する。 # それぞれname,countsに分けてデータフレームを作成する。 df = pd.DataFrame(index=[],columns=['name','counts']) for k, v in a.analyze(text): add_list = pd.Series([k,v],index=df.columns) df = df.append(add_list,ignore_index=True) # グラフの背景を白くする。 # Colaboratoryのダークモードだと、透過してnameが見えなくなるため plt.rcParams['figure.facecolor'] = 'white' df.index = df.name df[df.counts > 2].sort_values('counts',ascending=False).plot(kind='bar',figsize=(15,5))

まとめ
- 1つの記事で名詞の出現頻度を知ることができるようになった。
- アライさんがでてくることはわかりやすいが、他の「Twitter」や「アカウント」などの出現回数が少ないため、なんの記事なのかこれだけでは判断が難しいかもしれない。
- 次はクローリングして、名詞を収集してなにかできないか模索する。
テキストマイニング(前回の続き)
概要
前回までのあらすじ
- ここまでできました。

今回やること
SourceCode
- BeautifulSoupとurllibをimport
- 指定したURLからhtmlを取得
- 取得したhtmlから本文を抜き出し、形態素分析にかける
# BeautifulSoupとurllibをimport from bs4 import BeautifulSoup import urllib #urlを指定して、dataにhtmlを格納 url = u'https://headlines.yahoo.co.jp/hl?a=20190417-00000073-impress-sci' response = urllib.request.urlopen(url) data = response.read().decode('utf-8') # dataから特定のタグ内のテキストをmainに格納 soup = BeautifulSoup(data) main = soup.find('p',class_="ynDetailText yjDirectSLinkTarget") #---ここからは同じ t = Tokenizer() tokens = t.tokenize(main.text) for token in tokens: print(str(token))
- 出力はこんな感じ
テキストマイニング
テキストマイニングとは
テキストマイニング(英: text mining)は、文字列を対象としたデータマイニングのことである。通常の文章からなるデータを単語や文節で区切り、それらの出現の頻度や共出現の相関、出現傾向、時系列などを解析することで有用な情報を取り出す、テキストデータの分析方法である。(出典:Wikipedia)
Pythonで実装する
概要
Install
- まずは、pipでjanomeをインストール
pip install janome
SourceCode
- 以下のような形でソースを書くと形態素に分解してくれます。
t = Tokenizer() tokens = t.tokenize(u'こんにちは。私は日本人です。') for token in tokens: print(str(token))
こんにちは 感動詞,*,*,*,*,*,こんにちは,コンニチハ,コンニチワ 。 記号,句点,*,*,*,*,。,。,。 私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 日本人 名詞,一般,*,*,*,*,日本人,ニッポンジン,ニッポンジン です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス 。 記号,句点,*,*,*,*,。,。,。
Next
■
概要
- Bokehによるエネルギーデータの可視化
- pandasの使い方は下記を参照するとすごく幸せになれます。
- データ分析で頻出のPandas基本操作
- StatsFragments
- 初心者による「Python初心者がコピペで使える!時系列データの可視化!」でのBokeh分になります。
importライブラリ
from bokeh.io import output_notebook, show from bokeh.plotting import figure, output_file, show from bokeh.layouts import column from bokeh.models import DataSource,RangeTool,HoverTool import bokeh.palettes as bp output_notebook() import pandas as pd import numpy as np
使用データ
# データの読み込み df = pd.read_csv(r'sample_data.csv',names=['date','pointA','pointB','pointC'],skiprows=[0],engine='python',index_col=[0],parse_dates=[0]) df.index.freq = 'H' df.dropna().head()

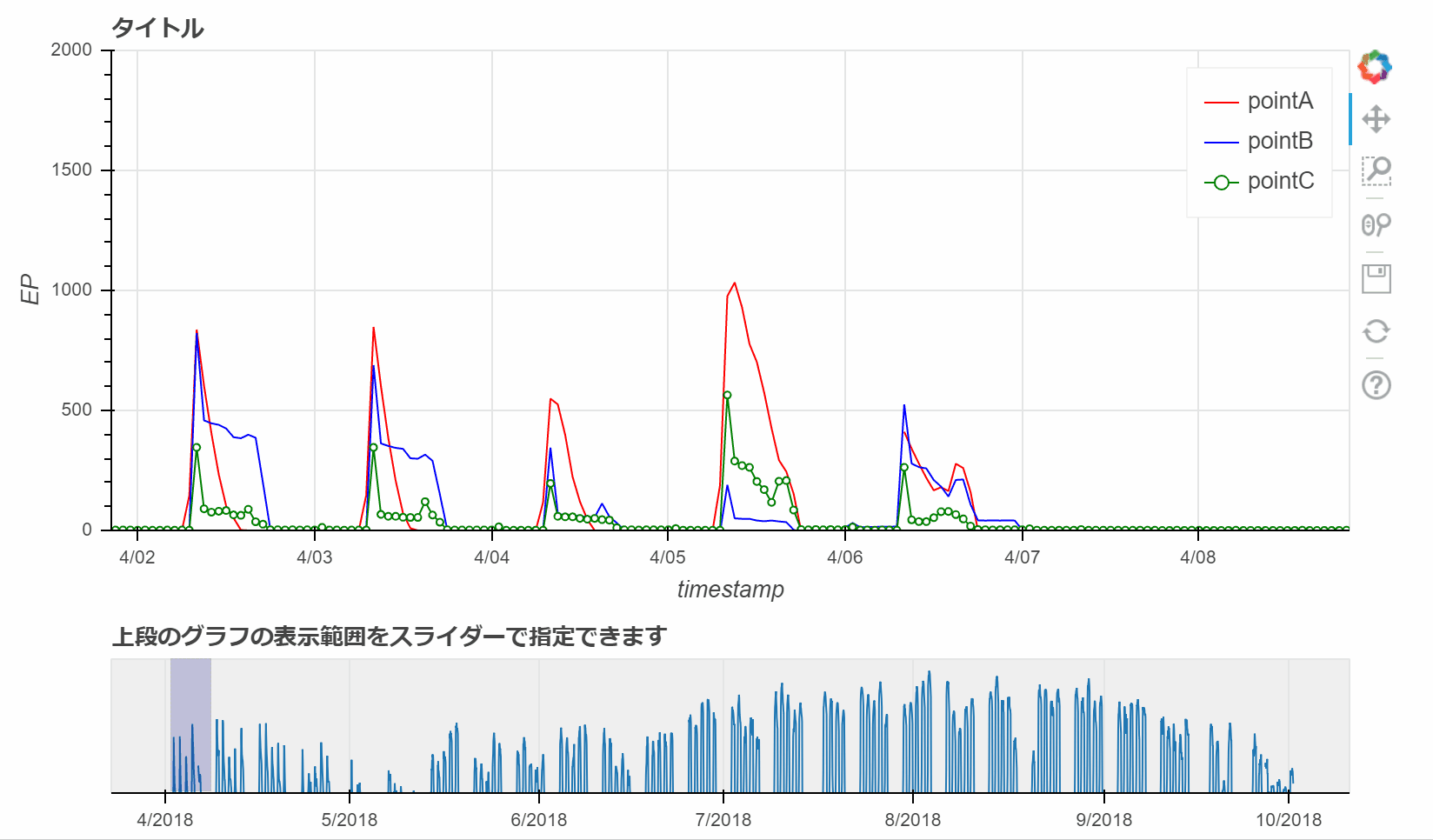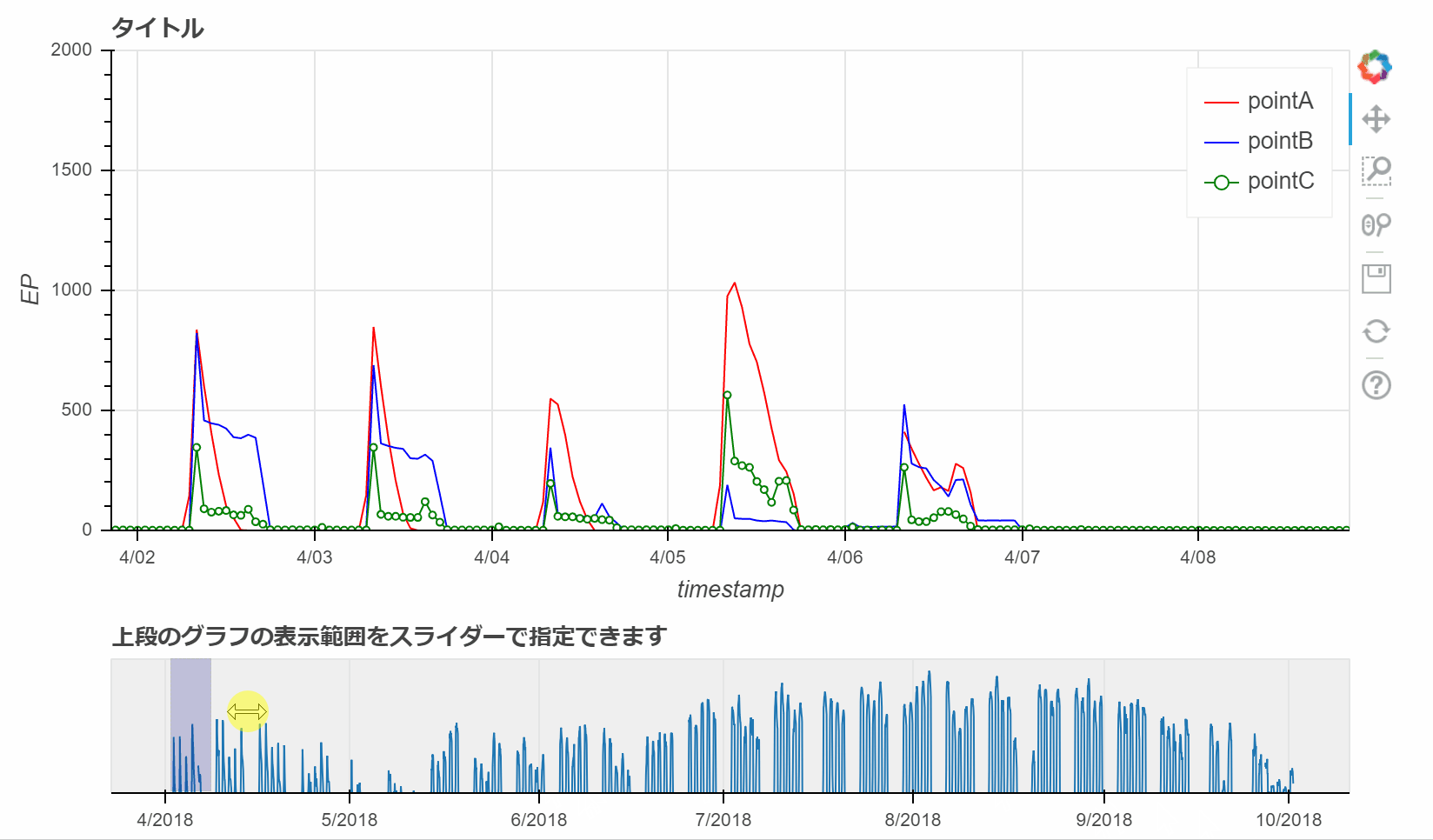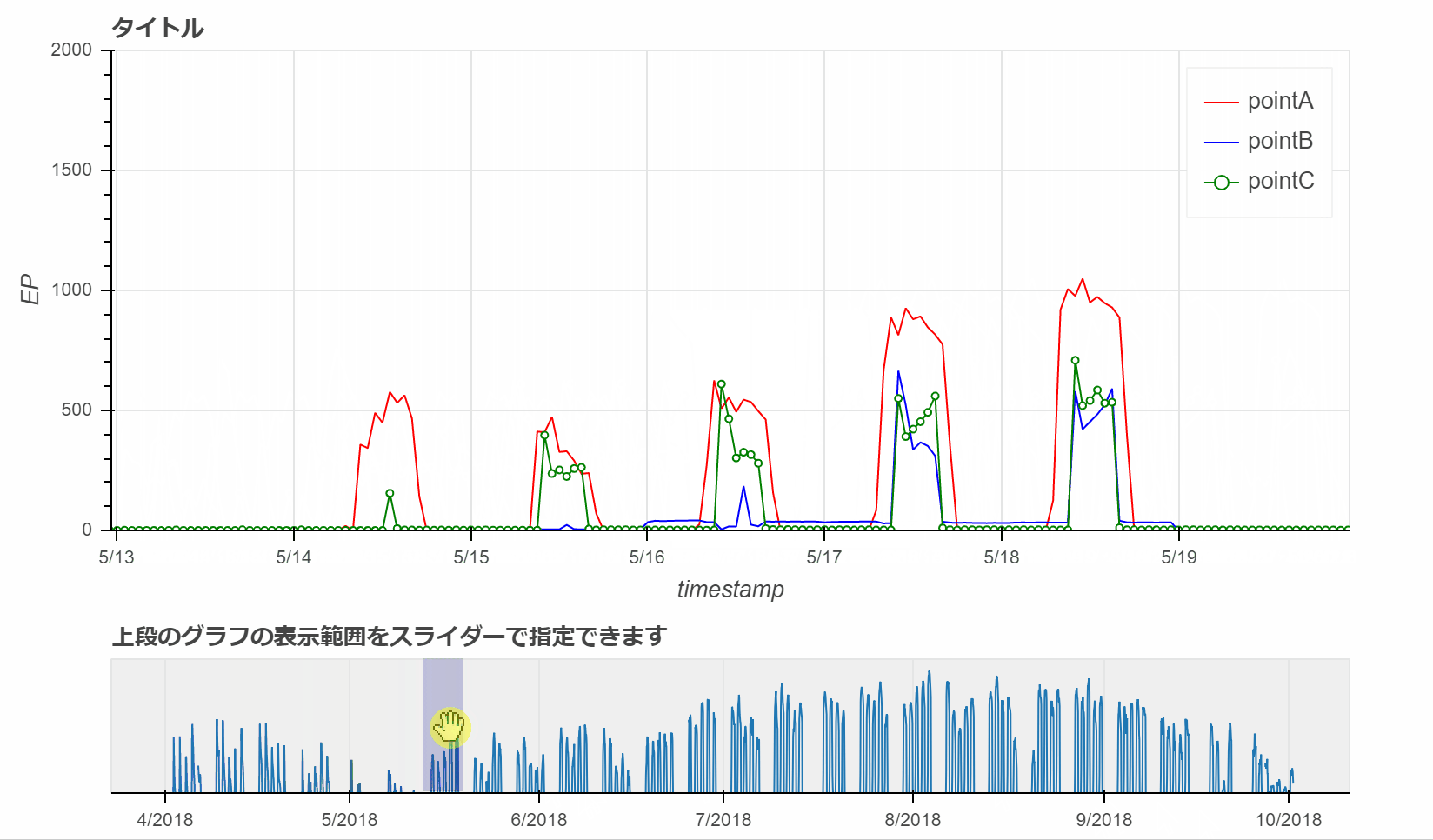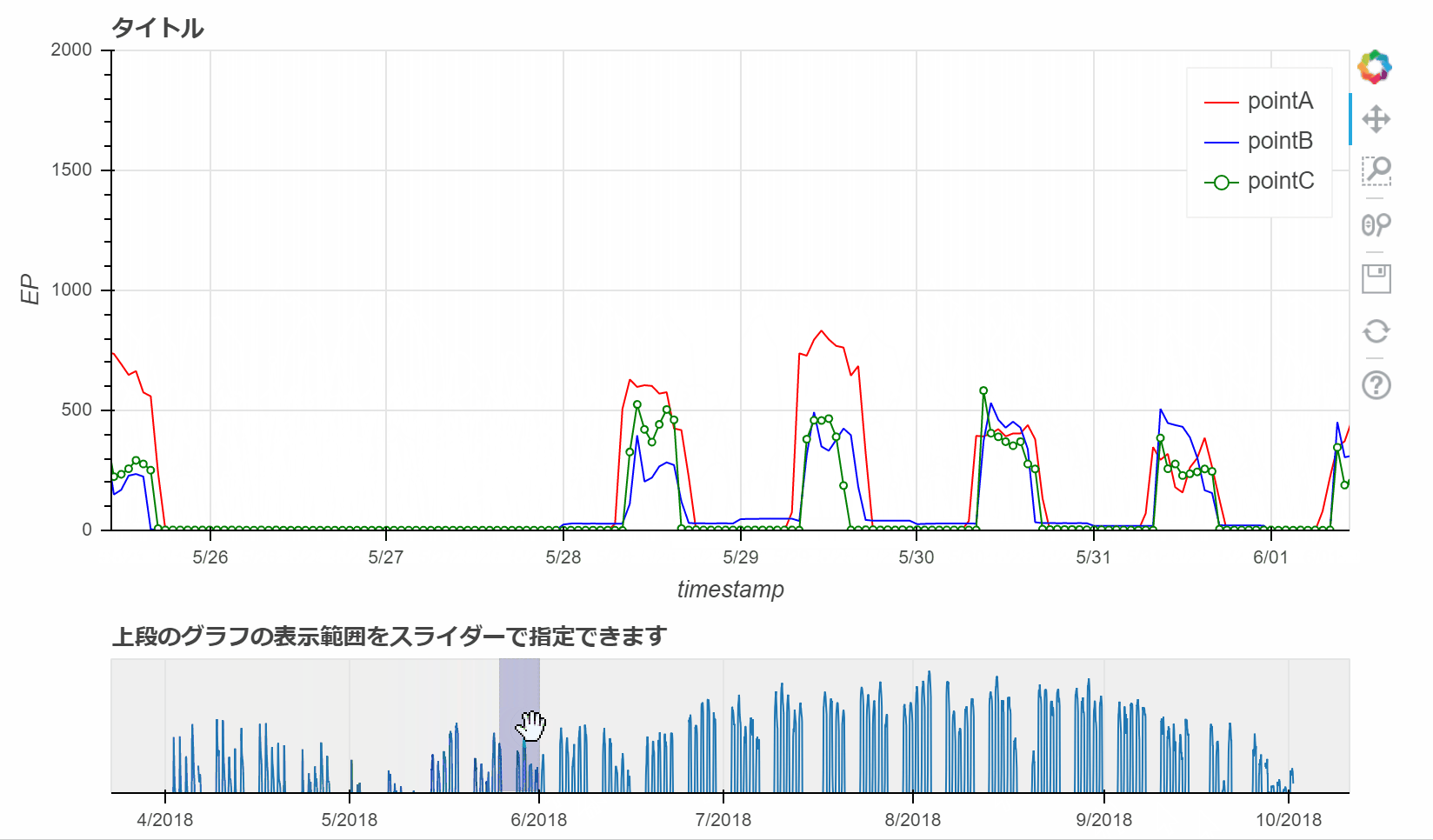
Bokehによるグラフ
- Bokehによる線グラフ
- bokehによる線グラフは下記のコードで実装できます。
- 適宜変数の値は変更してもらえればと思います。
# 適宜'pointA'などの文字列を変更してください。
pointA = 'pointA'
pointB = 'pointB'
pointC = 'pointC'
# グラフの設定
p = figure(title='タイトル', # タイトルを入力
x_axis_type='datetime', # x軸が時系列のindexを持っている場合、datetimeを指定
x_axis_label='timestamp', # x軸のラベル
y_axis_label='EP', # y軸のラベル
x_range = [df.index[0],df.index[168]], # x軸のレンジ(list型)
y_range = [0,2000], # y軸のレンジ(list型)
width=800,height=350, # グラフの幅と高さの指定
)
#適宜追加したいグラフ分だけp.line()を追加してください。
# pointAの線グラフを追加
p.line(x=df.index,y=df.loc[:,pointA],color='red',legend=pointA)
# pointBの線グラフを追加
p.line(x=df.index,y=df.loc[:,pointB],color='blue',legend=pointB)
# pointCの線グラフを追加
p.line(x=df.index,y=df.loc[:,pointC],color='green',legend=pointC)
# pointCのマーカーを追加
p.circle(x=df.index,y=df.loc[:,pointC],color='green',fill_color='white',legend=pointC)
# rangetoolの作成
# rangetoolは、上記で追加したグラフの描画範囲をスライダーで変更することができます。
# rangetool用のグラフの設定を追加
select = figure(title="上段のグラフの表示範囲をスライダーで指定できます",
plot_height=130, plot_width=800, y_range=p.y_range,
x_axis_type="datetime", y_axis_type=None,
tools="", toolbar_location=None, background_fill_color="#efefef")
# Rangetoolの設定
range_rool = RangeTool(x_range=p.x_range) # Rangetoolのx_rangeの範囲を設定(p.x_range)
range_rool.overlay.fill_color = "navy" # overlay.fill_colorはスライダーの色を指定
range_rool.overlay.fill_alpha = 0.2 # 透明度の指定
select.line(x=df.index,y=df.loc[:,pointA])# p.lineと同様に、x軸とy軸の設定
select.ygrid.grid_line_color = None
select.add_tools(range_rool) # range_roolを追加
select.toolbar.active_multi = range_rool
# グラフの描画
show(column(p,select))
- Bokehによる棒グラフ
- 1dayにリサンプリングして棒グラフにしています。
# 1データdayの可視化(棒グラフ)
day_df = df.resample('D').sum()
# グラフの設定
p2 = figure(title='タイトル', # タイトルを入力
x_axis_type='datetime', # x軸が時系列のindexを持っている場合、datetimeを指定
x_axis_label='timestamp', # x軸のラベル
y_axis_label='EP', # y軸のラベル
width=800,height=350 # グラフの幅と高さの指定
)
# caution
# bokehのx_axis_typeはmsの分解能をもっているため、barの太さを1日分にするには
# 下記のようにms → 1dayに直す必要がある。
day_width = 1000* 3600 * 20 # ms * hour * 1day(隙間をあけるために20にしています)
# pointAの棒グラフを追加
p2.vbar(x=day_df.index,top=day_df.loc[:,pointA],color='red',legend=pointA,width=day_width)
# pointBの棒グラフを追加
p2.vbar(x=day_df.index,top=day_df.loc[:,pointB],color='blue',legend=pointB,width=day_width)
# pointCの棒グラフを追加
p2.vbar(x=day_df.index,top=day_df.loc[:,pointC],color='green',legend=pointC,width=day_width)
# pointCのマーカーを追加
p2.line(x=day_df.index,y=day_df.loc[:,pointC],legend=pointC,color='black')
show(p2)
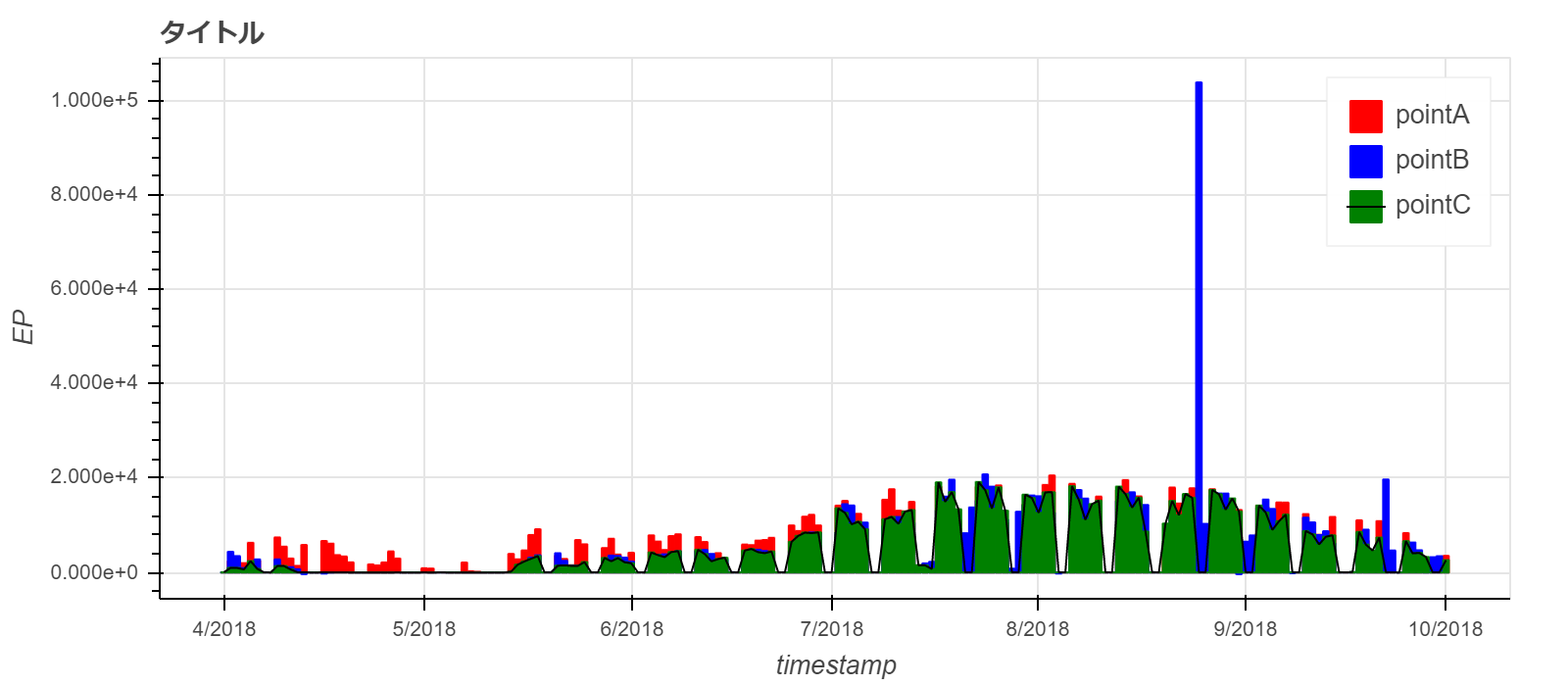
まとめ
- Bokehでデータを可視化し、スライドバーを導入することで、データフレームを細かく分割せずに一気に長期間を確認することができる。
- 報告書等にまとめる際は、適宜画像を保存する必要がある。
- Bokehはすごく便利なことがわかった!今度からこれ使おう。